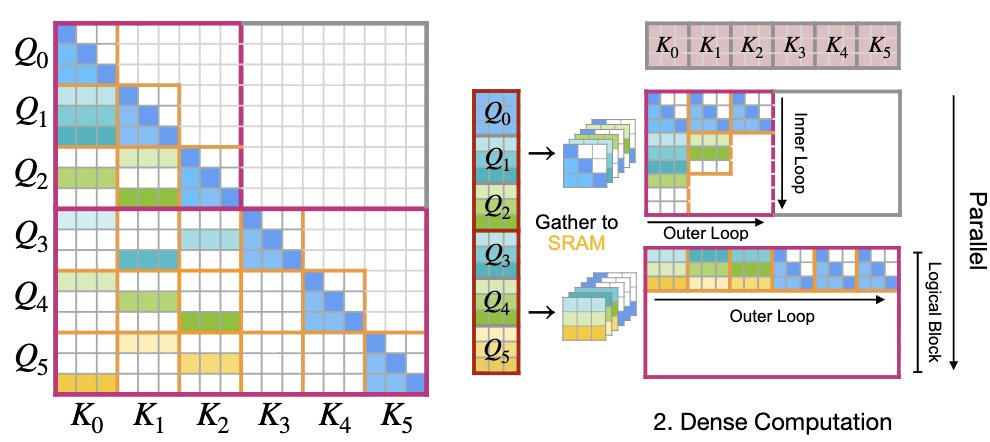
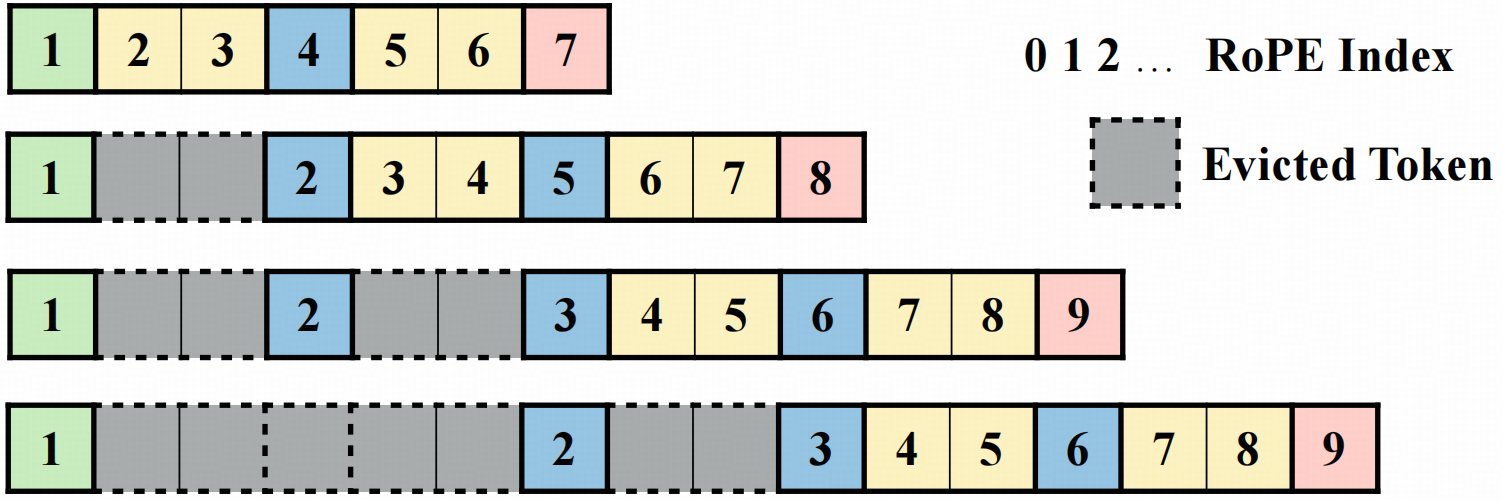
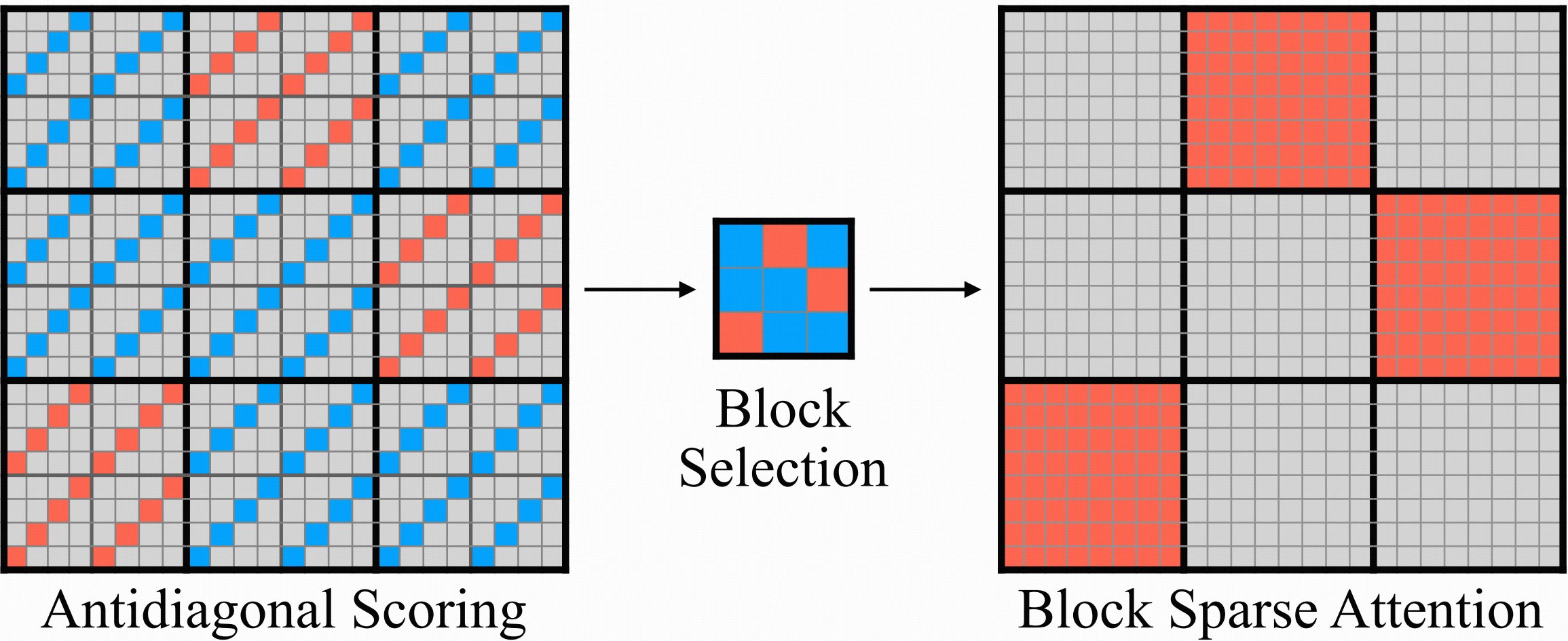
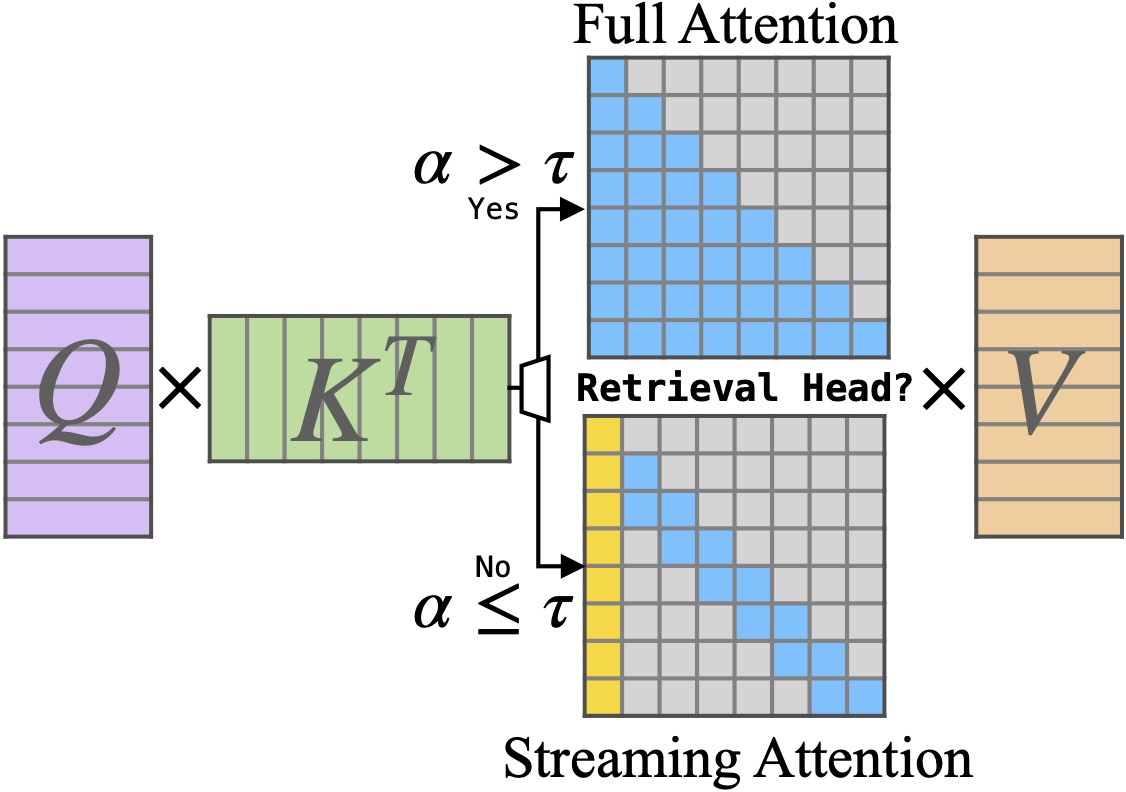
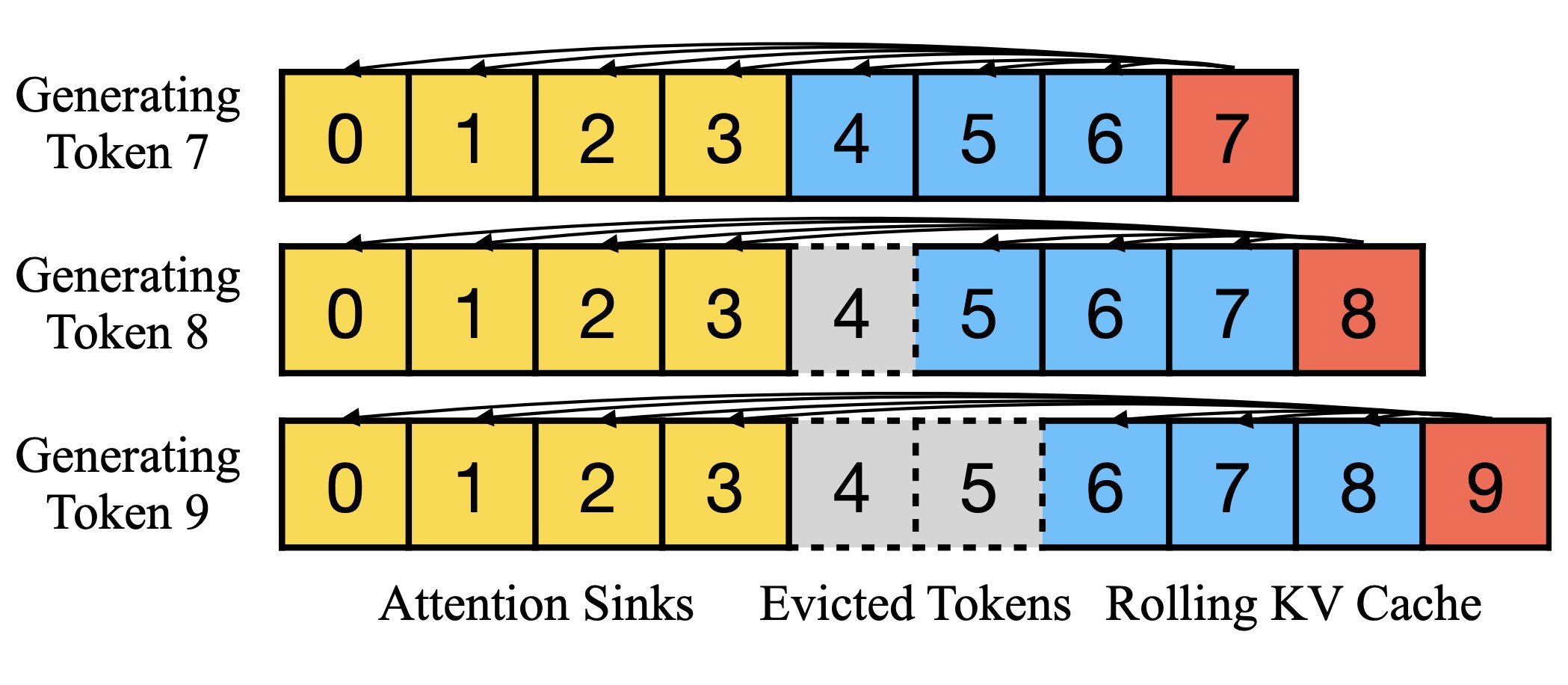
Linear: O(d)
Softmax: O(ed)
Softmax: O(ed)
September 1, 2025
How much information can attention mechanisms store? Using relative error analysis, we show that linear attention scales linearly with head dimension while softmax attention scales exponentially with head dimension.